AI in the enterprise
– 9 min read
The hidden costs of generative AI

Andrew Miller

Just because an enterprise company can develop custom software doesn’t mean they should. There’s a perception that a DIY (in-house) solution is more cost-effective or can achieve use cases perfectly tailored to the company’s needs. That’s not always the case.
Generative AI is particularly complex. There are numerous technology vendors to select from. Stitching these vendors together can be slow, risky, and resource intensive, and results often don’t meet the accuracy needed to move from proof-of-concept to production.
On top of that, the technology is evolving at an unprecedented pace, which means more maintenance for the solution to remain effective. And for generative AI to be an effective enterprise solution, it needed to dynamically connect to internal data to provide the most accurate, high-quality responses.
Hiring, development, and maintenance all come at a price. Enterprise companies need to factor in those costs when considering DIY generative AI versus licensing a full-stack platform.
- Implementing generative AI for enterprise use is complex. It’s slow, risky, and resource-intensive to build a solution in-house.
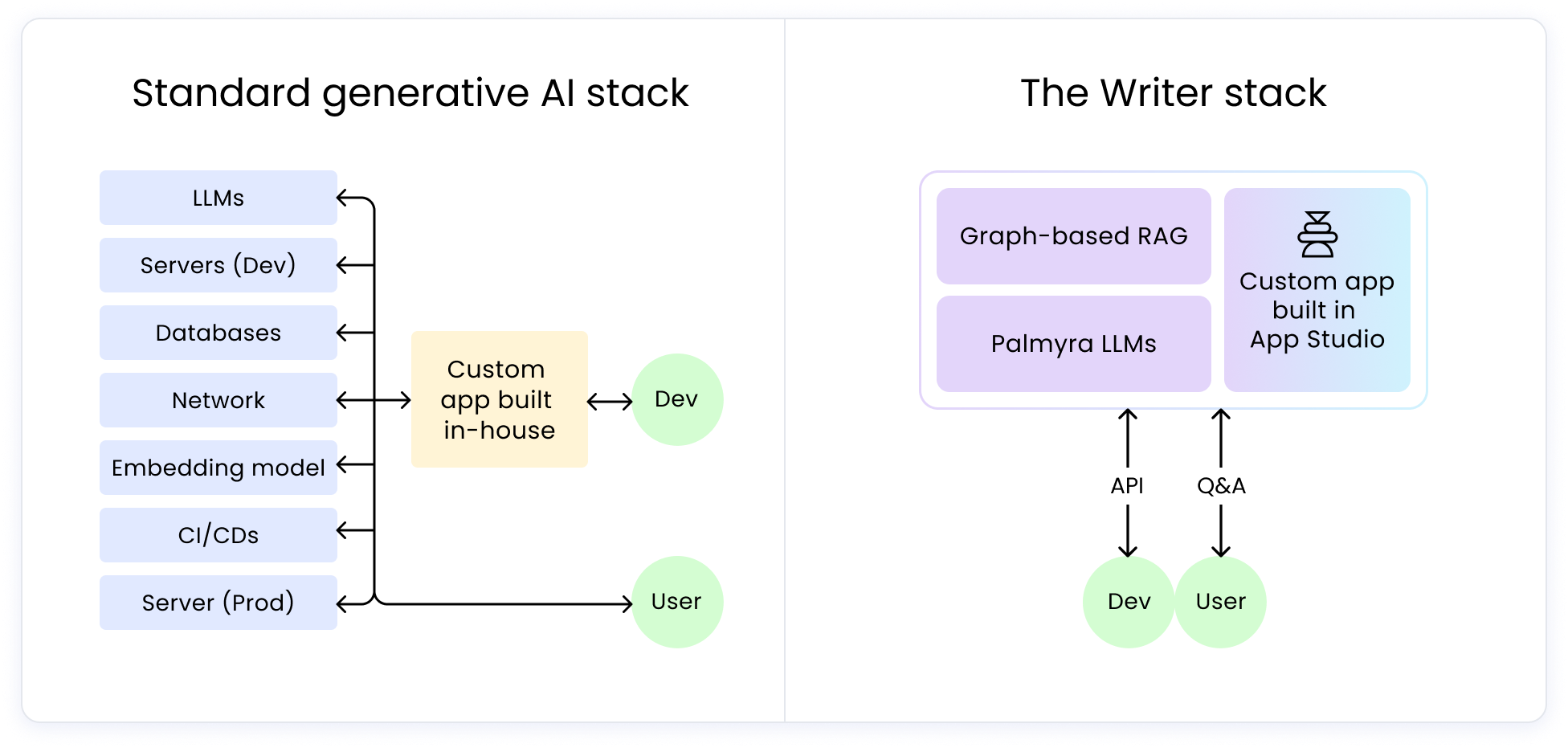
- DIY generative AI has hidden costs such as development and production servers, databases, storage, and the need for a large language model (LLM) and retrieval augmented generation (RAG) approach.
- A full-stack platform eliminates the costs of servers, storage, and in-house resources, but involves annual platform fees, onboarding costs, and monthly subscription costs.
- Full-stack solutions offer faster deployment, higher output quality, better security, and easier ROI achievement compared to DIY generative AI.

The hidden cost of DIY generative AI
Generative AI will have a few things in common with other solutions developed in-house. You’ll need to pay for development and production servers, databases, and storage. Critically, you’ll need to pick a large language model (LLM), and a retrieval augmented generation (RAG) approach.
An LLM is the foundation of generative AI: massive datasets that use machine learning algorithms and natural language processing to generate output. There are various LLM builders available, all of which have pros and cons. Skill-specific models, like image analysis, can be great for narrowly defined use cases but fall short for general use cases. Picking a general-purpose model, like GPT-4, may seem like a smarter choice, but these models are often very large and cost-prohibitive when used at scale.
The most impactful generative AI solutions often use RAG. Rather than guessing or “hallucinating” (as AI is known to do), with RAG, responses are grounded in your internal company data, allowing users to analyze and ask questions specific to your business use cases.
A common way of implementing RAG is vector retrieval, which uses a combination of vector databases and embedding models. Embedding models convert data for storage in a vector database.
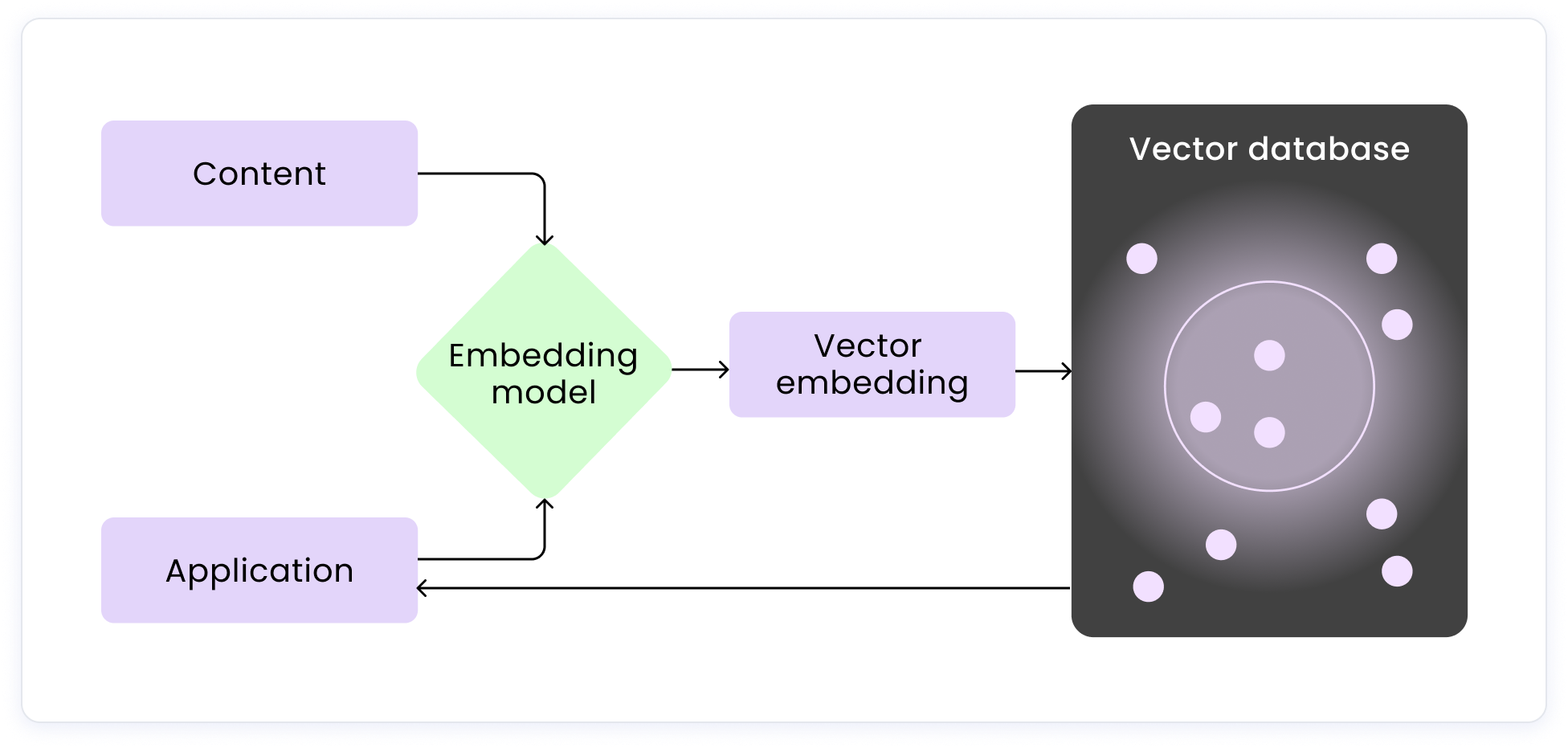
However, building your own RAG solution can become expensive fairly quickly. A RAG solution can commonly require 2–3 engineers to build and maintain a system.
Once set up, your primary cost will be your cost per query, which can be broken down into two main parts:
- Vector storage cost: The most important factor will be how much data you’d like to store, and how many replicas you’d like to maintain. Data storage amounts are fairly straightforward and depend on your use case, while replicas depend on latency. The more replicas you have, the more concurrent queries your vector retrieval solution can process.
- LLM RAG costs: When asking questions of your vector DB, normal LLM costs apply. These are usually calculated by tokens or characters in your prompt. What can make RAG particularly expensive is that you’re often filling up your context window with chunks of documents that you’d vector retrieval method identified as relevant to your query. For more expensive models like GPT-4, these costs can get quite high.
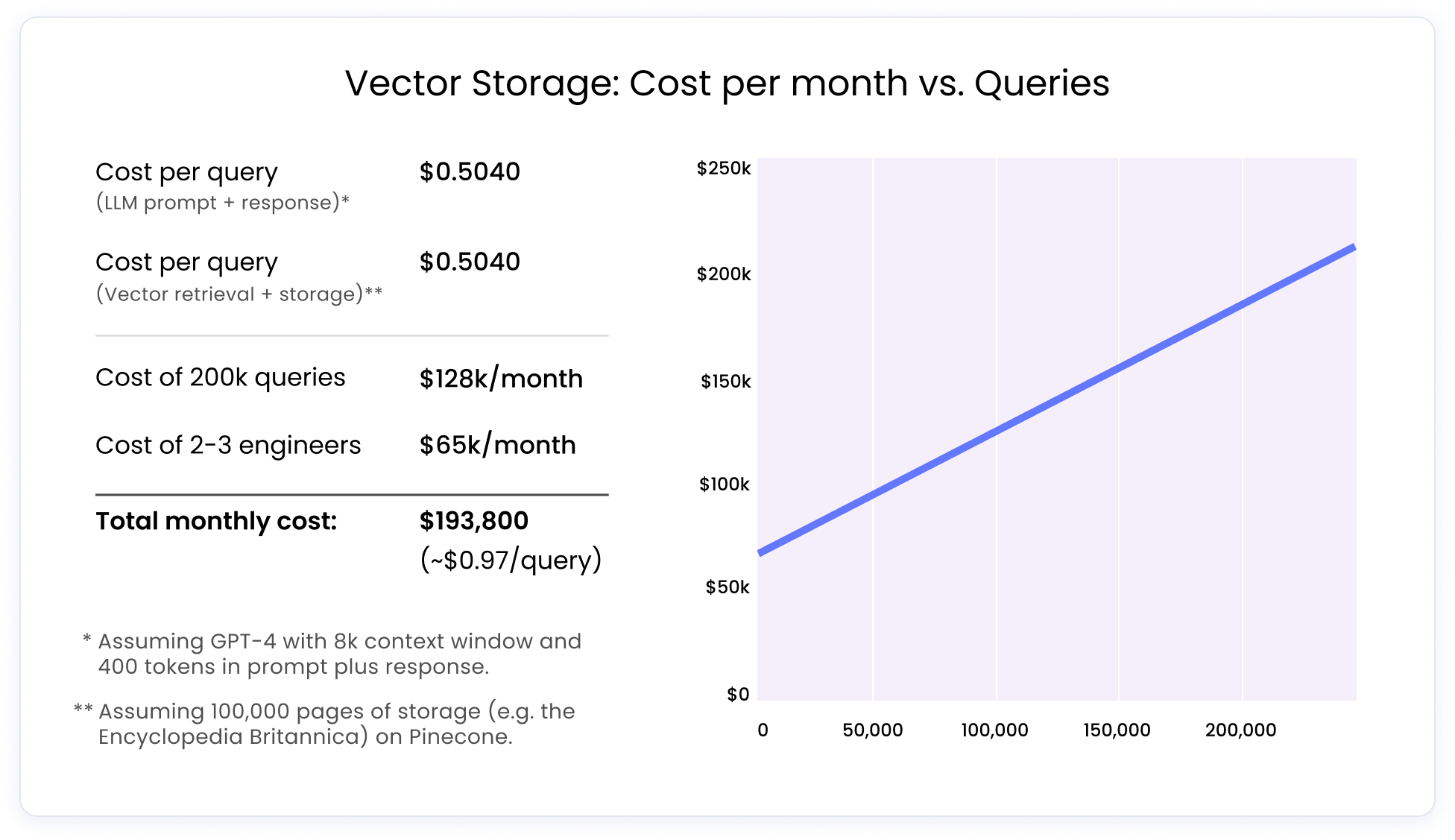
Let’s look at an example. Assume you’re a mid-sized enterprise looking to process about 200k queries a month. Your database has about 100k pages for product FAQs, research docs, and more — roughly equivalent to the Encyclopedia Britannica. The resulting cost is estimated to be over $190k per month.
Next, you’ll need to develop an application for your users. This might be a chat interface or a UI that walks users through a series of inputs and uses that information to create a prompt.
To be the most effective, the application needs to be “where your users are” — both for easy access and to fit into their existing workflows. It also needs to be flexible enough to support multiple use cases, which might mean a chatbot and a UI.
The total cost of ownership of a full-stack platform
With any licensed full-stack solution, you’re immediately eliminating the costs of servers, storage, and in-house resources (at least those associated specifically with the project).
And, like any licensed product, you’ll have associated costs for access to a full-stack generative AI solution, including any of the following:
- Annual platform fees to access the product, which can vary by vendor.
- Onboarding costs to train your users.
- Monthly subscription costs, such as per seat or by query volume (or both).
You may need to rely on internal resources, such as an engineer, to help with the initial setup. But outside of that, a full-stack platform has already integrated the services required — an LLM and RAG — so your users can immediately begin testing and implementing use cases.
Unlike vector databases, Knowledge Graph from Writer connects internal company data sources for richer RAG that can preserve semantic relationships and encode structural information.

After the initial setup, your internal resources will be minimally involved, such as adding new users or staying up to speed with newly released features. Both of these functions would be similar to what’s needed for a DIY solution — and easier to manage with a full-stack platform.
With Writer, you also benefit from our expertise. We help enterprise companies with adoption and change management so you can build the right use cases and AI apps for your business.
Read more: The key roles to drive success in generative AI implementation
Things to consider when comparing the two approaches
Comparing the hard costs is only one part of the equation. There are other factors to consider that are harder to quantify but definitely impact your organization’s ability to effectively implement and scale generative AI.
Time to deployment
When you build a generative AI solution in-house, you’ll need to consider the amount of time involved, on top of the resources. It could take an engineering team months — or even years — to piece together the disparate services you need for generative AI. If you don’t have engineers with the right expertise, then on top of that you’ll need time to hire.
Writer recently ran a survey with Dimensional Research and found that 88% of companies building in-house solutions need six months or longer to have a solution operating reliably.
A full-stack solution allows you to realize value faster. You can implement use cases with a solution like Writer within a few weeks.
Check out how to map AI use cases for fast, safe implementation.
Quality of output
Most LLMs are for general-purpose use cases, so they’re trained for a breadth of knowledge and skills, including casual users and personal use cases.
As our report shows, 61% of companies building DIY solutions have experienced AI accuracy issues. Most consider their output as mediocre or worse, with only 17% indicating that their DIY solution is excellent.
You need a model that’s designed for business. This leads to higher accuracy and better results for your users. Without the focus on business output, your users may spend a lot of time editing, which doesn’t help your organization realize as much value from the DIY solution. Additionally, users may become frustrated if they have to spend a lot of time editing.
By contrast, the Writer approach to retrieval-augmented generation, combined with Palmyra LLMs, has accuracy that’s almost twice as accurate as common alternatives.
Security
Our survey found that 94% of companies consider data protection a significant concern with generative AI. Depending on your industry, your data may need to meet security and compliance standards, such as SOC 2 Type II, PCI, or HIPAA.
When you integrate an LLM into your DIY solution, you’re often giving up control over your data. The vendor often has the right to access, retain, and use your data as part of the generative AI responses — from any user, at any organization, accessing the same LLM. Your data isn’t segregated or protected.
You’ll also need to consider security within the DIY solution, which can be spread across the disparate components used.
A full-stack generative AI platform has security built-in, from user access to how your data is used within the product.
Change management
Generative AI represents a big shift in how people get work done. To get the most value out of AI, you need to identify the right use cases. You also need to train your teams to use the tool and help with adoption. This all comes with an additional cost and can impact the ROI of your project.
Your total cost of ownership impacts ROI
Software success is often measured by its ROI, and the cost is a key consideration in the calculation. With DIY generative AI, the hard costs alone can be substantial, especially as query usage increases across the organization. Add in additional factors such as time, quality, and security, and it becomes even harder to reach ROI.
Meaningful ROI comes from implementing a solution that can deliver at the pace that the technology develops. With a DIY solution, you may find that you’re always “playing catch up” with allocating the resources, time, and technology needed to match generative AI developments.
As a result, you’ll always have a gap between what your DIY solution can produce, and what’s possible. And generative AI isn’t a technology where you want to be behind the curve. Unsure how to achieve ROI with generative AI? Follow this six-step path.
More resources

AI in the enterprise
– 8 min read
The future of talent: Adapting your hiring practices for an AI workplace
Alaura Weaver

AI in the enterprise
– 8 min read
Making the most of AI without compromising data privacy
Alaura Weaver

AI in the enterprise
– 8 min read
Supporting existing employees in the face of AI disruption
Alaura Weaver